
How to Monitor AI in Radiology: A Practical Framework for Post-Deployment Governance
What process, product, and people monitoring requires in practice, and why the accountability always rests with the institution


.png)
Most institutions deploying clinical AI have thought carefully about validation. Many have also thought carefully about what comes after.
The gap is not awareness. It is implementation. Post-deployment monitoring is understood as a requirement. What remains unclear, particularly for institutions managing multiple AI solutions across complex environments, is what it actually looks like in practice, how to resource it, how to scale it, and how to demonstrate it independently when regulators or clinical boards ask.
Monitoring AI in radiology after deployment requires visibility across three distinct dimensions: the technical performance of the system, the stability of the algorithm over time, and how clinicians actually interact with AI outputs in practice. Without all three, an institution cannot demonstrate that its AI solutions are performing safely and under the EU AI Act(1), that demonstration is no longer optional.
If your institution deployed an AI solution in the last two years, the question worth asking is not whether it worked during validation. It is whether you would know if it stopped working last month.
At our webinar in March 2026 exploring post-deployment AI governance, Dr. Geraldine Dean, AI Lead at Epsom and St Helier NHS Trust and AI Clinical Lead at Unilabs/TMC, shared what building a monitoring framework at scale actually looks like in practice. With fifteen active AI solutions deployed across seven countries and more than a thousand users, her team's experience offers one of the most grounded perspectives available on what post-deployment surveillance requires.
What are the three dimensions of clinical AI monitoring?
Drawing on the Royal College of Radiologists' guidance published in March 2026(2), Dr. Dean structured the monitoring challenge across three dimensions: process, product, and people.
Process monitoring addresses the technical layer. Are AI results being generated consistently? What percentage of cases receive an output? How quickly are results delivered? These are hygiene factors, but they matter. An AI solution that runs intermittently or returns results too slowly to influence the reporting workflow is not delivering clinical value, regardless of its accuracy.
Product monitoring addresses algorithm performance. Are the KPIs consistent with what was observed during validation? Is performance stable over time? Is there any signal of drift? This is where most institutions focus their governance attention, and where regulatory frameworks such as the EU AI Act are placing increasing obligations on deployers.
People monitoring is where institutions most often fall short. It addresses how clinicians actually interact with AI outputs, whether they are using the tool as intended, whether automation bias is emerging, and whether behaviours such as cherry-picking or underuse are developing. Of the three dimensions, it is the least mature, the least resourced, and the least discussed. That is precisely why it deserves the most attention.
Why is human-AI interaction the hardest dimension to monitor?
Dr. Dean was direct on this point. "I worry more about human drift than AI drift," she said during the session. Not because algorithm performance matters less, but because human-AI interaction is the dimension institutions are least equipped to observe and least prepared to act on.
The risks are specific. Automation bias, where clinicians increasingly defer to AI outputs without independent review, can develop gradually and invisibly. Skill atrophy is a longer-term concern, particularly for trainees entering clinical practice with AI present from day one. As Dr. Dean put it, a third-year registrar (resident or fellow) using AI is not the equivalent of a consultant (senior physician). The hierarchy of clinical development still matters. If AI is always present, the question of whether clinicians are developing the autonomous judgment they need becomes harder to answer and harder to monitor.
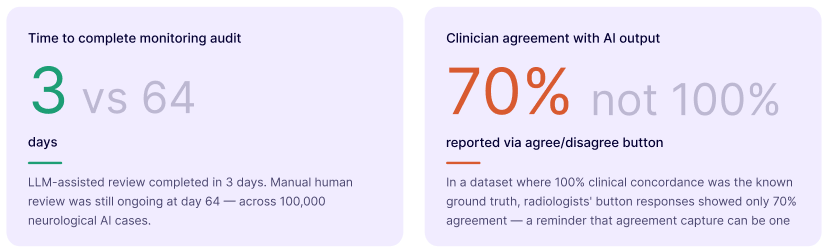
One practical entry point for capturing human-AI interaction data is the agree-disagree button, a single additional click in the reporting workflow. Dr. Dean's team found something instructive when they studied it: in a dataset where 100% agreement between the human and AI output was known, radiologists' button responses reflected only 70% agreement. The gap between what clinicians believe they are doing and what the data shows they are doing is itself a governance signal.
But the button may not scale. For complex, multi-output AI solutions, confirming agreement with every individual finding is not a realistic ask of a reporting radiologist.
How do you monitor AI at scale across multiple solutions and sites?
Three days versus sixty-four days. That is the difference Dr. Dean's team observed between LLM-assisted extraction and purely human review when monitoring a neurological AI solution producing over a hundred findings per case across 100,000 cases. At day sixty-four, the human review was still ongoing.
This is the central operational challenge. Monitoring one binary AI solution is manageable. Monitoring fifteen solutions, each producing multiple outputs, across seven countries, is not. Manual auditing cannot keep pace. Doing nothing is not acceptable.
Dr. Dean's team has been exploring LLM-assisted monitoring cautiously and strictly within controlled environments. In one study involving a thousand CT-PE cases, an LLM was tasked with extracting whether pulmonary embolism was documented as present or absent in both AI outputs and human reports. The LLM-derived metrics were closer to the reference standard of four independent radiologists than the agree-disagree button data. The direction of travel is clear, though Dr. Dean was careful to note that confidence in the safety and ethics of these approaches must precede their adoption at scale.
LLM-assisted monitoring does not replace clinical judgment. It creates the scale at which clinical judgment can be applied meaningfully, surfacing signals that would otherwise remain invisible in the volume of daily practice.
What is the minimum acceptable level of AI monitoring?
Not every institution has the resources of Unilabs or a dedicated AI Centre of Excellence. But Dr. Dean was clear that some level of monitoring is non-negotiable, not only as good clinical practice, but as a legal obligation under the EU AI Act for deployers.
The minimum is not a dashboard. It is the ability to answer a specific question: Is this AI solution continuing to work safely in our environment, for our population, within its intended use? Institutions that cannot answer that question independently cannot defend their deployment decisions when clinical boards, regulators, or patients ask. And they will be asked. When that question is asked, the institution bears the accountability, not the vendor whose dashboard showed green.
The practical starting point Dr. Dean described is a structured auditing process, some form of agreement capture, and a commitment to revisiting performance at defined intervals. Not perfect. But defensible. And a foundation from which more sophisticated monitoring can be built as resources and evidence allow.
Where does clinical AI monitoring need to go next?
At the close of the session, Dr. Dean was asked where she hopes the field will stand by March 2027. Her answer was specific: more collaboration between clinical, technical, and behavioural experts; stronger regulatory pressure generating more real-world evidence; and a more standardised process that makes meaningful monitoring accessible regardless of institutional resources.
The challenge is not a lack of understanding that monitoring matters. It is the absence of standardised, accessible frameworks for doing it well. The RCR guidance published in March 2026 is a meaningful step. The growing body of real-world evidence from institutions like Unilabs and Epsom and St Helier is another. What remains is closing the gap between what institutions know they should do and what they have the infrastructure to do in practice.
deepcOS® Insights is designed for exactly that gap: vendor-neutral, continuous monitoring of AI solutions across the full clinical lifecycle, built for institutions that understand that governance is an operational responsibility, not a procurement checkpoint.
Watch the full webinar to hear Dr. Dean and Dr. Julia Moosbauer go beyond what is covered here, including the live poll results from the session, the full human-AI interaction mitigation framework, and the audience Q&A where institutions shared their own monitoring challenges in real time: Watch Now
Frequently asked questions
What does post-deployment AI monitoring mean in radiology?
Post-deployment monitoring in radiology refers to the continuous oversight of AI solutions after they have gone live in clinical practice. It covers three dimensions: process monitoring, which tracks whether AI results are being generated reliably; product monitoring, which assesses whether algorithm performance remains consistent with validation; and people monitoring, which examines how clinicians interact with AI outputs over time.
What does the EU AI Act require from healthcare AI deployers?
The EU AI Act places obligations on deployers, not only vendors, to monitor AI systems, detect risk, ensure human oversight, and retain logs of system performance. For healthcare institutions, this means post-deployment surveillance is a legal requirement, not a best practice recommendation.
What is automation bias in radiology AI?
Automation bias occurs when clinicians increasingly defer to AI outputs without applying independent clinical judgment. It develops gradually and can be difficult to detect without structured monitoring of human-AI interaction patterns, such as agreement rates, review behaviour, and workflow adherence.
What is the difference between AI drift and human drift?
AI drift refers to degradation in algorithm performance over time as patient populations, scanner protocols, or clinical workflows change. Human drift refers to changes in how clinicians interact with AI outputs, such as increasing reliance on AI findings without independent verification. Both require monitoring, but human drift is currently the less well-understood and less well-monitored of the two.
Can LLMs be used to monitor clinical AI performance?
Early evidence suggests that LLM-assisted extraction can reliably derive performance metrics for binary AI systems and may scale to more complex, multi-output solutions. Dr. Geraldine Dean's team found that LLM-derived metrics were closer to an expert reference standard than agreement button data in a study of CT-PE cases. However, deployers must be confident in the safety and ethics of any LLM-assisted approach before adopting it at scale.
How should institutions start monitoring AI if resources are limited?
A structured auditing process, some form of clinician agreement capture, and a commitment to reviewing performance at defined intervals represent a defensible starting point. The priority is establishing a baseline, even an imperfect one, from which monitoring practice can develop as resources and evidence allow.
.jpg)

.png)
.avif)
